Honyaku Entry

As we learned in the last post, the generator parses files in various directories, and then based on the contents of those files invokes some code dynamically to generate parts of the site.
In this post, I’ll describe how the individual pages are parsed in preparation for the generation phase. As well as some tricks that I employ to make working with YAML a nicer experience.
Entry Type
Each page has a data-driven representation for that page entry in the site. This is what informs the generator what kind of page to generate for a given entry.
#[derive(Clone,Debug)]
pub struct HonyakuEntry {
// The underlying data - specific to the kind of content.
pub data: HonyakuEntryData,
// The paths that are used for traversing into this content.
// (The source dirnames can differ from the published destination dirnames.)
pub paths: TraversalPaths,
// The visual order of this entry, compared to its siblings.
// (This controls what order the entries are presented in a selector).
// (Also used to predictably sort elements that release at the same time.)
pub sequence: usize,
// Tags to associate with this content (not used much in the current site).
// One usage of this is in Siren for marking gameplay videos and cutscenes.
pub tags: Vec<Tag>,
// The title of this page.
pub title: Arc<AnalyzedTranslation>,
}
This is the final form of the entry, but as you’ll notice by a lack of a Deserialize attribute, it’s not a format that we can read from disk. Instead it’s a post-deserialization, and post-runtime manipulation type.
The format of the type that is read from disk looks like this:
#[derive(Clone,Debug,Deserialize)]
struct HonyakuEntryFile {
// Same as `HonyakuEntry`
pub data: HonyakuEntryData,
// Controls the mapping of the source directory to the target directory.
// (If `None`, then the destination directory is identical to the source.)
pub id: Option<HonyakuEntryId>,
// Same as `HonyakuEntry`
#[serde(default)]
pub tags: Vec<Tag>,
// Similar to `HonyakuEntry`, except it's not "analyzed" yet, and optional.
pub title: Option<Translation>,
}
So, as you can see, there’s some key differences between the content as you parse it, and the content within an actual HonyakuEntry instance.
Another thing to note that can be easy to miss is that HonyakuEntryFile is private. Nobody outside of HonyakuEntry deals with this type, so it’s purely there to help us construct the final HonyakuEntry type.
General Programming Advice:
I find that it’s best to construct types in such a way that you get complete, fully-initialized types back from the public functions constructing them. And then, you should try hard to keep the internal state of the type valid.
I see many issues in larger code-bases where people expose types that follow a two-pass strategy, like:
let mut instance = Instance::new(); instance.initialize();In almost all programming languages this can be either avoided, or hidden from the caller so that it happens as a part of constructing and returning the instance to the user.
I’m not saying anything radical here, to some of you this is a “well, duh!” sort of comment. But I see this basic principle broken very often in practice.
Initial File Parsing
To start, let’s look at an example non-selector YAML file:
id: !Transform RemoveZeroPadding
data: !Manga
dates:
released: !include ../../publish_date.md
updated: "2024-08-16T12:31:46-07:00"
published: "2023-12-28T23:30:00-08:00"
comics:
- $ref: C01/index.yaml
- $ref: C02/index.yaml
summary: !include summary.md
As you can see, our YAML parsing has a few extensions present in it nonstandard to normal YAML parsing. To implement these extensions, I like working with dynamic representations of the data.
So, what you can do is parse the value into some dynamic, abstract data type. Then you can do whatever mutations you want to on the data that may happen at runtime. And then you can finally try to parse the dynamic type into a static one.
So when we start “processing” a file, it looks something like this:
impl HonyakuEntry {
pub fn from_path(generator: &Generator, path: &Path, idx: usize) -> Result<Arc<Self>> {
let mut value: Value = serde_yaml::from_reader(
BufReader::new(File::open(path.join("index.yaml"))?)
)?;
// ... Process the rest of `value` here ...
}
}
And Value here represents literally any valid YAML content. (Don’t worry, we’ll enforce that it fits a more specific type structure later on.)
Publishing and Updating Content
The dates type actually looks like this in code:
#[derive(Clone,Debug,Default,Deserialize)]
#[serde(deny_unknown_fields)]
pub struct ResourceDateTimes {
// The time that the content was released (CD, manga, etc).
#[serde(default)]
pub released: Option<DateTime<Utc>>,
// Only present if the translation is "live" (released).
#[serde(default)]
pub published: Option<DateTime<Utc>>,
// Only present if the translation is "live" (released).
#[serde(default)]
pub updated: Option<DateTime<Utc>>,
}
This is the primary type which controls how content is published.
Not all content has dates. For instance, dates don’t really make sense for selector pages. They kind of just inherit their dates based on their children.
Still, it’s beneficial to treat publishing content predictably, and since HonyakuEntry is the best place to add functionality relating to this, we try to handle publish and updates here.
The process for updating dates looks like this:
- If
data.datesis not present, skip this logic. - For
published, ifpublished == "pending", replace the value with the generation time. - For
updated, ifupdated.is_none() && published.is_some(), then replace the value with the generation time. - If the CLI flag
--publishis provided, then after making these updates we will overwrite the file on disk with the updated contents.
This makes it really easy for me to work locally on content, prepare to publish it throughout the week, and then finally --publish it when it’s time. If content is pending, then it acts as if it is published at generation time, but it doesn’t actually update any YAML files - making it easy to change my mind later and remove the pending tag.
If I want to update content and reflect that in things like Atom feeds, I just delete the updated field. Then, on next publish the updated field is filled with the current generation time.
And finally, if I’m working on something long-term, I just don’t provide any of these fields, they aren’t updated or published. This will still generate the page, but it won’t make it easy to find, because it wont be linked into the parent selector (so you have to know the exact URL to find the page).
Pages that aren’t published or published: pending will:
- Still generate (so that I can work on the translation).
- Will not generate Atom events (so nobody is notified of the page).
- Will not link into the parent selector (so you can’t easily access the page).
- Will not be present in the controls to move between content pages.
You can see this right now, actually. This page is not currently published. It’s pending me adding translations, and has a template with all blank lines.
If you’re reading this in the future, that may no longer be true, but the page looked like this at the time of this blog post:
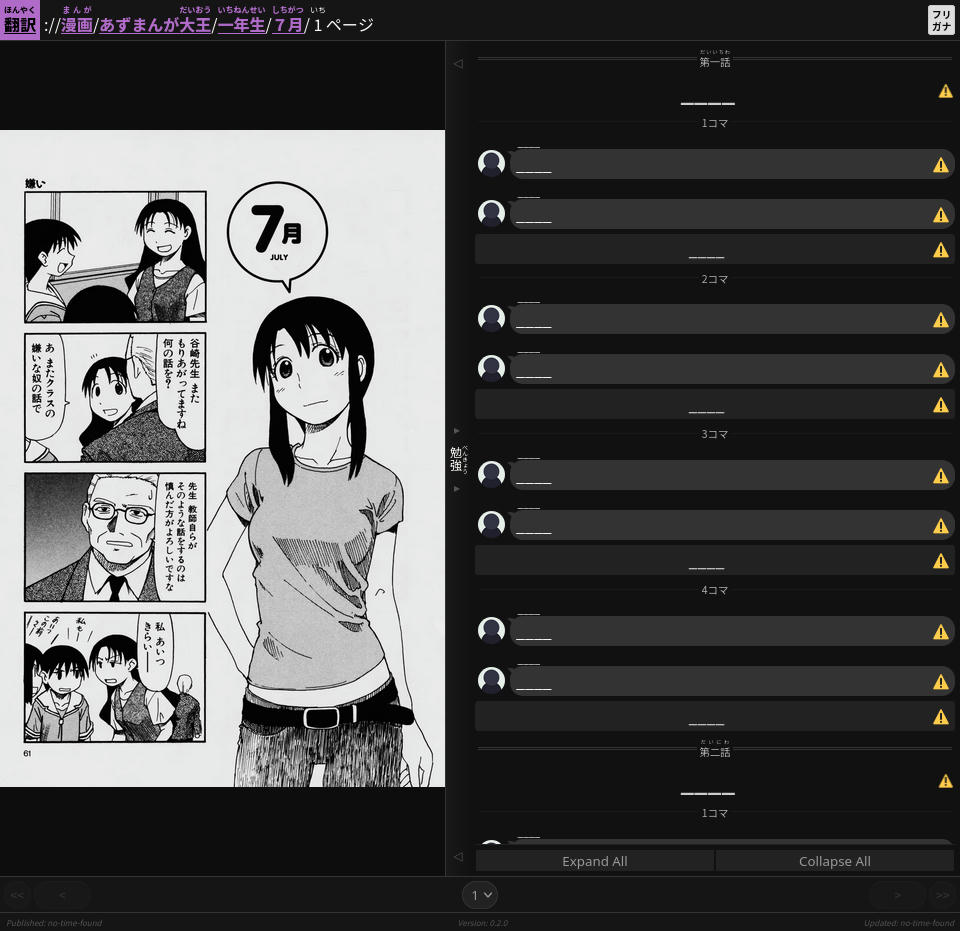
Resolving the Full YAML
After updating the dates, we will not be writing the YAML file back out to disk any more. However, we have to resolve our YAML extensions before parsing to an actual type.
$ref Pointers
One extension is to say that keys with the name $ref are actually pointers to some other YAML value inside (or outside) of the document.
In this case, it’s really handy to be able to say the parts of the file are outside of the document. This allows us to not have one huge YAML file, and instead split our data up into multiple files.
So, when you see $ref: path/to/file.yaml, that really says something like: “read that YAML file, resolve extensions on it, then pretend like it was written in-line at this location”.
Looking back at our example above that means that this:
id: !Transform RemoveZeroPadding
data: !Manga
dates:
released: !include ../../publish_date.md
updated: 2024-08-16T12:31:46-07:00
published: 2023-12-28T23:30:00-08:00
comics:
- $ref: C01/index.yaml
- $ref: C02/index.yaml
summary: !include summary.md
Is actually this (after expanding the two $ref pointers):
id: !Transform RemoveZeroPadding
data: !Manga
dates:
released: !include ../../publish_date.md
updated: 2024-08-16T12:31:46-07:00
published: 2023-12-28T23:30:00-08:00
comics:
- title:
jpn: "4月"
eng: "April"
subtitle:
jpn: "[April Part-A]"
eng: "April Part-A"
cells:
- $ref: K01.yaml
- title:
jpn: "ゆかり先生"
eng: "Ms. Yukari"
cells:
- $ref: K01.yaml
- $ref: K02.yaml
- $ref: K03.yaml
- $ref: K04.yaml
summary: !include summary.md
And then in turn, those $ref pointers are also resolved to even more YAML (relative to the directory that we were in for the prior resolved YAML file).
To illustrate this better, it might be easier to just provide the directory tree for this content entry:
${SOURCE}/manga/azumangadaioh/001/001/001
├── C01
│ ├── index.yaml
│ └── K01.yaml
├── C02
│ ├── index.yaml
│ ├── K01.yaml
│ ├── K02.yaml
│ ├── K03.yaml
│ └── K04.yaml
├── cache.yaml
├── comic.tiff
├── index.yaml <-- The root YAML we were parsing.
└── summary.md
!include Directive
Sometimes, you don’t want to include more YAML data, instead you want to put a large piece of string data somewhere and then import it in some other YAML file.
This is what the !include directive allows us to do.
It basically says “read this file, and then pretend like that ‘value’ was here”. The value is not treated like YAML content - the whole file is one value (even if it’s formatted as YAML). For my purposes it’s always interpreted as a string, though I could imagine wanting to define this a little better.
Note:
I’m actually not sold on this design, it might be better to name this differently, or use some explicit key names like
$include_stringto specify how we should interpret the content we’re including.For now this works, but I don’t think it’s good generally in practice, so I’ve made it an optional feature on my YAML resolver that is off by default.
This is used here in two ways:
- To have a consistent, shared
publish_datefor the manga. - To allow the summary file to be stored and updated separately (for convenience).
I admit, it’s not the most useful here, but one place it’s really useful is for these articles. I write them in regular markdown files, and then I !include them into the YAML tree.
Like this:
title:
jpn: "[Honyaku Entry]"
eng: "Honyaku Entry"
data: !Article
dates:
published: pending
markdown: !Analyzable
contents: !include index.md
translations:
- text:
jpn: "1ページ"
eng: "Page 1"
Disallowing Unknown Fields
An issue with YAML is that you can type a field name wrong, or you can have something indented improperly, or something like that and things can parse incorrectly.
While this won’t completely fix the issue, one way that you can combat these problems is by disallowing unknown fields wherever possible. This is one of the ways you can harden YAML parsing so that the parser will reject fields that it doesn’t understand.
It’s a simple thing, but something you could accidentally miss if you aren’t setting your parser up properly.
Note:
It’s not always a good idea to be so strict about your schema, but here there is no reason not to be strict. (Since we control all of the data and all of the code)
Parsing to HonyakuEntryFile
Finally, we can now parse the value into an actual typed object.
So our current code looks like this:
impl HonyakuEntry {
pub fn from_path(generator: &Generator, path: &Path, idx: usize) -> Result<Arc<Self>> {
let mut value: Value = serde_yaml::from_reader(
BufReader::new(File::open(path.join("index.yaml"))?)
)?;
update_data_dates_and_reserialize(generator, path, &mut value)?;
// Resolve the rest of the value using the YAML resolver. This will do
// things like resolve $ref pointers, and fill in !include directives.
let mut resolver = YamlResolver::with_options(YamlResolverOptions {
allow_include_directive: true,
});
let value = resolver.resolve_value(path, Path::new("/"), value)?;
// Finally parse the value, this is a private intermediate type.
let entry: HonyakuEntryFile = serde_yaml::from_value(value)?;
// ... Process the rest of `entry` here ...
}
}
The things we still need to fix are constructing paths, and resolving and analyzing the title. After we do that, we can finally construct the goal type; HonyakuEntry.
Building TraversalPaths
In a perfect world, we would just map the source and destination 1:1. However, I wanted to use naturally-incrementing numbers for some URL paths (1, 2, 3, etc). However, on the filesystem I want to store things that sort alphabetically. Since we’re dealing with numbers, that means we need zero padding (001, 002, 003, etc).
The final destination path is called the id here. The reason is because we use the path to uniquely identify the content entry. (I’ve flipped back and forth on whether or not I actually like this or want something separate like a UUID, but I’m feeling indifferent about it these days, it works well enough.)
For the most part, we don’t explicitly state id. If an id is not provided, then it is inherited from the source. When we do state an id it’s usually a transformation of the source, like id: !Transform RemoveZeroPadding.
The types relating to HonyakuEntryId look like this:
#[derive(Clone,Debug,Deserialize)]
enum IdTransformation {
RemoveZeroPadding,
}
#[derive(Clone,Debug,Deserialize)]
enum HonyakuEntryId {
Transform(IdTransformation),
Explicit(String),
}
And the final destination dirname for the entry is calculated like this:
let Some(source) = path.file_name() else {
return Err(anyhow!("no basename on file path: {}", path.display()));
};
let destination = match entry.id {
Some(HonyakuEntryId::Transform(t)) => match t {
IdTransformation::RemoveZeroPadding =>
source.trim_start_matches('0').to_string(),
}
Some(HonyakuEntryId::Explicit(id)) => id,
None => source.clone(),
};
Note:
This is a bit simplified, as you may know
Pathtypes are not the same asstrorStringtypes. There are some conversions going on here. One improvement I’d like to make to the code in the future is to drop thePathtype and pivot to usingUtf8Path. This code doesn’t need to handle the myriad of different kinds of not-valid-UTF8 paths you can form on Unix, so the very-generalPathtype is more a hinderance than a help here.But you should still be able to get the gist of what I’m doing.
Resolving title
If you recall the beginning of the post, HonyakuEntryFile doesn’t require us to have a stated title, but HonyakuEntry enforces that all entries must have a title (and that they need to be “analyzed”, whatever that means).
There’s a few places where we can get a title from:
- A separate constructor can be provided an explicit title for entries not backed by YAML files on the disk.
- The
HonyakuEntryFileroot can optionally have a title defined in it. - Finally, all underlying data types know how to construct a default title if the entry is not named otherwise.
All of these are used in different places.
For example, the game Siren has expected paths with expected titles. So when constructing them we pass in the expected titles and don’t rely on a real YAML file (option 1; supply an explicit title on construction of an entry).
Most other titles come from the HonyakuEntryFile root. This is by far the most common way to provide a title to an entry (option 2; defining the title within the entry file).
Finally, some content constructions benefit from just having the title generated. These are dynamically constructed, and account for names like for manga pages (option 3; a final generated title when no other title can be found).
This produces some Translation to act as a title, but it doesn’t produce an AnalyzedTranslation. (Reminder that Translation is just a structure with two fields; jpn and eng, which are both just raw String types.)
Analyzing a title
Honyaku has a really powerful feature called JapaneseAnalyzer.
The analyzer is present, and possible to get, from any Generator instance. So, we can use that to convert things from a Something to an AnalyzedSomething.
This is really worth its own separate blog post. However, I want to at least show the transformation code at the callsite. For now, you can think of this as just arcane magic that turns Japanese text from a String to some type called AnalyzedJapaneseText. We’ll explore what this actually means in a later blog post.
This brings us unceremoniously to the final complete function for parsing:
impl HonyakuEntry {
pub fn from_path(generator: &Generator, path: &Path, idx: usize) -> Result<Arc<Self>> {
let mut value: Value = serde_yaml::from_reader(
BufReader::new(File::open(path.join("index.yaml"))?)
)?;
update_data_dates_and_reserialize(generator, path, &mut value)?;
// Resolve the rest of the value using the YAML resolver. This will do
// things like resolve $ref pointers, and fill in !include directives.
let mut resolver = YamlResolver::with_options(YamlResolverOptions {
allow_include_directive: true,
});
let value = resolver.resolve_value(path, Path::new("/"), value)?;
// Finally parse the value, this is a private intermediate type.
let entry: HonyakuEntryFile = serde_yaml::from_value(value)?;
// Resolve the final destination that we will use for the generated site.
let Some(source) = path.file_name() else {
return Err(anyhow!("no basename on file path: {}", path.display()));
};
let destination = match entry.id {
Some(HonyakuEntryId::Transform(t)) => match t {
IdTransformation::RemoveZeroPadding => source.trim_start_matches('0').to_string(),
}
Some(HonyakuEntryId::Explicit(id)) => id,
None => source.clone(),
};
// Resolve some title that we want to interact with (option 2 or 3).
// (It's a different constructor that doesn't parse YAML for option 1.)
let title: AnalyzedTranslation = entry.title
.unwrap_or_else(generate_dynamic_title)
.into_analyzed(generator.analyzer())?;
Ok(Arc::new(Self {
data: entry.data,
paths: TraversalPaths {
destination,
source,
},
sequence: idx,
tags: entry.tags,
title: Arc::new(title),
}))
}
}
Summary
So this is the way all of the YAML files are parsed, and how we deal with big YAML files that are normally annoying to manage and maintain. There’s a few key ideas here that I really try to maintain in my code, which I think leads to nice results.
- We try to work with dynamic
Valuetypes for anything that involves dynamic generation (like updating fields, processing YAML extensions, etc). - YAML parsing has some extensions built into it to make things scale - working with big YAML files is no fun and easy to make mistakes on.
- We have a private type that acts as an intermediate before we construct the final type that we want to return to the user.
- Finally we return a completely-initialized entry instance, and rely on the rest of the automation to react to data in the type as appropriate.